
Hassan Ait Naceur 1*; Brahim Igmoullan 1; Mustapha Namous 2
1, Laboratory of Georesources, Geoenvironment and Civil Engineering (L3G), Faculty of Sciences and Techniques, Cadi Ayyad University, Marrakesh, Morocco
2, Data Science for Sustainable Earth Laboratory (Data4Earth), Sultan Moulay Slimane University, Beni Mellal, Beni Mellal-Khenifra, Morocco
E-mail:
hsngeo@gmail.com
Received: 13/10/2024
Acceptance: 05/11/2024
Available Online: 05/11/2024
Published: 01/01/2025

Manuscript link
http://dx.doi.org/10.30493/DAS.2024.483211
Abstract
Flooding is a significant hazard, resulting in the devastation of infrastructure and loss of life. This research seeks to forecast flood susceptibility in the Oued Lakhdar watershed in the Moroccan High Atlas by combining the Frequency Ratio (FR) statistical model with three machine learning algorithms: Random Forest (RF), Decision Tree (DT), and Support Vector Machine (SVM). High-resolution Google Earth imagery and field data were utilized to delineate 154 flooding occurrences, resulting in a thorough inventory map. Moreover, multiple data sources were analyzed to create thematic maps of various conditioning elements, resulting in the selection of 11 pertinent factors following a multicollinearity assessment. The findings indicate that the FR-SVM model had exceptional performance, with an area under the curve (AUC) of 93.32%. The FR-RF and FR-DT models exhibited commendable performance, with AUCs of 91.64% and 89.41%, respectively. Moreover, the FR-SVM model achieved a sensitivity of 95.88% and a specificity of 97.64%, illustrating its ability to minimize false positives while reliably identifying at-risk regions. The generated maps delineate regions with a heightened risk of flooding, especially in the northern section of the basin and adjacent to rivers with gentle slopes. These findings offer a solid foundation for decision-makers to enhance flood prevention and mitigation efforts in this susceptible area. Moreover, the outstanding efficacy of the developed FR-SVM model underscores its validity in analogous conditions in semi-arid regions.
Keywords: Flood susceptibility, Machine learning, SVM, Frequency ratio, Random forest
Introduction
Flooding transpires when a river exceeds its natural banks, resulting in the inundation of adjacent regions [1]. This event is regarded as one of the most catastrophic natural disasters, resulting in considerable material destruction and presenting a substantial risk to human life [2]. The hazards of flooding mostly stem from river overflows, the failure or deterioration of riverbanks, and the increase in water levels linked to alterations in flow velocity and elevation [3].
Morocco’s position in a semi-arid region renders it especially susceptible to flood threats, which are intensified by climate change, as demonstrated by severe and tempestuous rains, particularly near summer’s end [4]. In recent decades, the nation, like many others globally, has encountered multiple deleterious hydrological occurrences impacting various regions. Flash floods are the most prevalent and perilous calamities in the nation due to their frequency, intensity, and unpredictability [5].
The Ministry of the Interior reports that 70% of the nation’s extreme weather events are floods, and the Directorate of Water Research and Planning has lately identified over 1,000 locations susceptible to flooding. A comparative review of flood risks in Morocco indicates that these events have inflicted considerable damage. Between 1980 and 2010, floods in southern Morocco caused about 1,036 fatalities and an economic loss of roughly 267 million USD, resulting in socio-economic instability in the region [6]. The annual direct economic damages from floods in Morocco are projected to equal 450 million USD [7].
In the future, Morocco is anticipated to experience an increase in both the intensity and frequency of flooding risk due to the exacerbated impacts of climate change [8]. Climate forecasts anticipate an increase in the frequency of extreme weather events. Furthermore, global warming not only elevates the incidence of severe storms and rainfall but also modifies hydrological patterns. The outcome is a decrease in soil infiltration and an augmentation in surface runoff. Consequently, existing vulnerable regions may encounter exacerbated impacts, heightening the socio-economic and environmental issues related to flood risk management.
Identifying flood-prone locations is essential for mitigating associated risks and losses, as well as for efficient land planning and management. The precise delineation of these at-risk areas facilitates the establishment of suitable management strategies and the enhancement of preventive and responsive actions. The probability of flooding is affected by several factors, including proximity to rivers, land use and type, drainage network density, slope, precipitation, and altitude [9]. Comprehending and measuring these elements is crucial for enhancing flood risk management and formulating more efficacious prevention tactics. Moreover, hydro-geomorphological techniques, which examine morphological characteristics from stereoscopic aerial imagery, can effectively designate flood-prone regions.
In recent decades, the geographical study of flood vulnerability has attracted considerable interest from researchers, who have utilized many methodologies to improve the comprehension and management of these hazards. Among these methodologies, expert-based techniques, including the Analytic Hierarchy Process (AHP), have proven to be effective [10]. Furthermore, bivariate and multivariate models have been utilized, encompassing the weight of evidence (WoE) [11][12], frequency ratio (FR) [13][14], information value (IV) [15], and logistic regression [16][17]. These methodologies provide diverse viewpoints for evaluating flood susceptibility, each uniquely enhancing risk management and preventative tactics. These statistical models frequently depend on linear assumptions to forecast variables. Nonetheless, due to the nonlinear dynamics often associated with flooding disasters, these models may occasionally yield erroneous outcomes. The intricate and diverse attributes of floods, including the non-linear interactions among risk factors, may not be sufficiently addressed by linear methodologies, hence constraining their precision and dependability in specific contexts [18].
Recent advancements in computational tools and access to high-quality data have prompted researchers to employ machine learning algorithms, including decision trees (DT) [19], random forest models (RF) [20][21], artificial neural networks (ANN) [22], and support vector machines (SVM) [23][24]. A significant number of these studies have concentrated on conventional machine learning models. Moreover, the majority of this study has employed a restricted set of variables for flood susceptibility modeling, while numerous additional aspects could improve the model. The application of hybrid methodologies that integrate machine learning models with statistical models, while considering a broader array of influencing factors, will enhance the accuracy and reliability of outcomes in flood susceptibility assessment.
This paper aims to evaluate flood susceptibility in the Oued Lakhdar watershed basin through a multi-faceted methodology. Eleven determining factors that influence the occurrence of floods were selected, including slope, elevation, aspect, lithology, land use, distance to rivers, precipitation, distance to roads, profile curvature, Topographic Position Index (TPI), Topographic Wetness Index (TWI), and Normalized Difference Vegetation Index (NDVI). A hybrid strategy integrating a statistical model with machine learning techniques was chosen to create a more precise and dependable flood susceptibility model. The outcomes derived from the Frequency Ratio (FR) model were utilized as input for three machine learning models: Decision Tree (DT), Random Forest (RF), and Support Vector Machine (SVM). This methodology leverages the advantages of each technique to more effectively consider the various elements affecting flooding, resulting in more reliable outcomes and a more precise evaluation of flood vulnerability in the Ouad Lakhder watershed.
Materials and Methods
Study area
The Oued Lakhdar watershed, encompassing approximately 1,277 km² upstream of the Hassan Premier dam, is situated in the western sector of the Azilal province within the Beni-Mellal Khénifra region. It is positioned between latitudes 30°28′ N and 31°28′ N and longitudes 110°04′ E and 110°32′ E (Fig. 1). The Lakhdar River, originating in the Zawyat Olmzi area, serves as a principal tributary of the Oued Oum Errabia. Topographically, the maximum altitude of the basin is 3,997 meters, with over 23% of the territory above 2,500 meters. The average slope degree is approximately 28.61°, with a maximum of 75°.
Geologically, the watershed is formed by Ordovician to Quaternary formations, with Jurassic terrain predominating. Morphologically, the southern part of the region is characterized by steep hills and high peaks, interspersed with long, narrow, and deep valleys. The area’s landscapes include high ridges, undulating plateaus, and deep valleys, offering a rich geomorphological and lithological diversity.

Data source
The requisite data for generating thematic maps of causative elements and compiling an inventory of previous flooding incidents (Fig. 2) were gathered and organized. The data utilized in this phase were acquired from multiple sources (Table 1). The data were subsequently converted and extracted to acquire the pertinent information for model training and validation. Machine learning algorithms were utilized for model training in a Python environment using Jupyter Notebook. The models’ performance was assessed to guarantee precision and dependability. The results were utilized to create flood susceptibility maps, classified into five risk levels (very high, high, medium, low, very low) employing ArcGIS software.

Flood inventory
Forecasting future flood vulnerability depends on an inventory map illustrating historical flood occurrences in a designated region. The fundamental principle is that future flood conditions are expected to mirror those of past occurrences [2]. This study generated the flood inventory map by examining high-resolution satellite imagery and integrating data from field surveys. A total of 154 flood locations were found. The dataset was randomly partitioned into two groups: the training set, consisting of 70% of the inventory sites (108 events), and the validation set, comprising 30% of the inventory sites (46 events) (Fig. 2). A 70/30 split is frequently employed for partitioning data into training and validation sets, despite the absence of a rigid guideline [25].

Flood conditioning factors
To create an accurate flood susceptibility map, it is essential to identify the most significant flood-driving factors [26]. Based on a literature review and available data, 12 key factors (distance to rivers, NDVI, slope, aspect, profile curvature, lithology, TWI, land use, precipitation, distance to roads, elevation, and TPI) were selected (Fig. 3).


Modeling approach
Multi-collinearity analysis
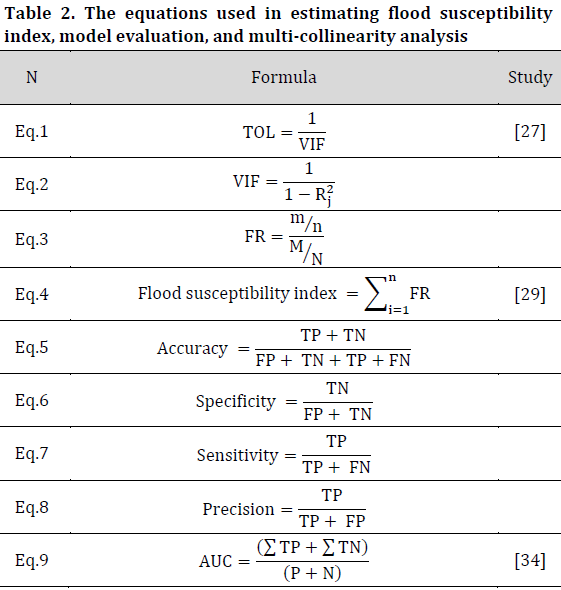
Given that multicollinearity among conditioning factors can compromise the accuracy of the predictive models, this study employs Variance Inflation Factor (VIF) and Tolerance (TOL) as measures to assess the presence of multicollinearity among the various conditioning factors. Any conditioning factors identified as contributing to multicollinearity will be removed from the original dataset. The calculations for VIF and TOL are provided in Eq. 1 and Eq. 2 [27] (Table 2) Where Rj2 is the coefficient of the determination for the regression analysis on all other variables.
Frequency ratio
The frequency ratio (FR) method is a straightforward methodology employed to evaluate flood susceptibility. This method is recognized for its straightforwardness and capacity to yield easily interpretable outcomes [28]. It operates by examining the frequency of historical flooding in connection to the selected parameters, including topographical characteristics and land usage. Regions that have already experienced flooding are more susceptible to recurrence under analogous conditions. The FR technique aids in forecasting potential flood locations by analyzing the frequency of flooding across various regions.
The FR can be computed as demonstrated in Eq. 3 (Table 2) where m denotes the number of flood points within each class of a given parameter, n represents the total number of flood points throughout the study area, M signifies the number of pixels in each class of the parameter, and N is the total number of points within the study area. The determination of flood susceptibility based on the FR model was performed using Eq. 4 [29] (Table 2).
Random forest (RF)
Random Forest is an algorithm that is comparatively straightforward to comprehend, expedient to train, and proficient in generating outcomes that generalize effectively. Nevertheless, it possesses a significant limitation: it functions as a black box, rendering results challenging to interpret. RF comprises a compilation of independent decision trees. Every tree possesses a limited viewpoint on the issue, attributable to a two-phase random selection (Fig. 4). This procedure encompasses a random sampling with replacement, referred to as “bagging,” and a random selection of variables, termed “feature selection.” This approach is particularly efficient in classification and regression problems, employing several decision trees that are randomly trained on diverse subsets of the data [15].
Decision tree (DT)
The DT algorithm, in particular C4.5, is commonly used for classification and regression tasks [30]. It consists of two stages: tree growth, where nodes are subdivided according to the most discriminating attributes and pruning to improve model generalization (Fig. 4). Decision trees are hierarchical models that divide input variables into homogeneous zones to predict outcomes. Although they are easy to interpret and effective at detecting non-linear relationships, they have limitations, such as sensitivity to noisy data and the inability to handle multiple outputs simultaneously. Various algorithms, such as CART, ID3, and C4.5, are used to construct these trees, each with its own criteria for measuring differentiation [31].
Support vector machine (SVM)
Support Vector Machine (SVM) is a supervised learning method grounded in statistical learning theory and the principle of structural risk minimization [32]. SVM is defined by two principal elements: the kernel function and the ideal classification hyperplane. The kernel function is initially employed to map the training dataset into a higher-dimensional space, facilitating linear separability of the data. The ideal hyperplane for classifying the data is established by maximizing the margin between samples from distinct classes, such as flood and non-flood samples (Fig. 4). The selection of the kernel function (including sigmoid, linear, polynomial, or radial basis function (RBF)) is pivotal to the efficacy of SVM. In this study, the radial basis function, recognized as the most commonly used kernel, has been selected [33].

Evaluation of model performance
The initial phase in validating the outcomes and assessing the model’s effectiveness include computing essential statistical measures, including sensitivity, specificity, accuracy, and precision. These indicators are crucial for evaluating the model’s accuracy in predicting natural risk susceptibility. Sensitivity denotes the ratio of flood grid cells accurately identified as flood occurrences. Specificity quantifies the ratio of non-flood grid cells correctly classified as non-flood by the model. Accuracy represents the total ratio of both flood and non-flood grid cells that the model accurately classifies. The four statistical indices can be calculated using the subsequent equations (Eq. 5-8) (Table 2).
Where: True Positive (TP) refers to the quantity of flood points accurately identified by the model as flood events. True Negative (TN) refers to the count of non-flood instances accurately identified by the model as non-flood. FP (False Positive) refers to the quantity of non-flood points erroneously classified by the model as flood events. FN (False Negative) refers to the quantity of flood points erroneously classified by the model as non-flood.
Furthermore, to evaluate the efficacy of the models utilized in this work, the Receiver Operating Characteristic (ROC) curve was used. This is a graphical depiction of the true positive rate (sensitivity) on the y-axis against the false positive rate (1-specificity) on the x-axis. The area under the curve (AUC) of the ROC offers a distinct metric for assessing a model’s capacity to differentiate across classes. A value of 1 signifies an exemplary model, whereas a value of 0.5 denotes a model without discriminatory capability. The AUC is computed using Eq. 9 [34] (Table 2)
Results and Discussion
TOL and VIF values
TOL and VIF values for the different independent variables indicate varying levels of multicollinearity (Table 3). Most variables, such as slope, aspect, rainfall, TPI, TWI, elevation, and distance to rivers, have VIFs below 3 and tolerances between 0.3 and 0.5. These values suggest low multicollinearity, which is generally acceptable for a reliable model. This means that these factors are not strongly correlated with one another and do not present significant collinearity issues [35].
However, some variables show signs of moderate multicollinearity, such as Curvature (VIF of 3.14, TOL of 0.318), Lithology (VIF of 3.11, TOL of 0.322), and NDVI (VIF of 3.37, TOL of 0.297). In contrast, the Land use factor stands out with a VIF of 13.70 and a tolerance of only 0.073, indicating very high multicollinearity. This level of correlation suggests that Land use is strongly linked to other factors. Therefore, this factor was omitted from the modeling process.

Correlation analysis between flood events and conditioning factors
The analysis of the correlation between flood episodes and conditioning factors, utilizing the frequency ratio (FR) approach (Table 4), revealed that regions with low slopes (0-5°) exhibit a FR of 5.31, indicating a significant sensitivity to flooding, whereas steep slopes (35-75°) demonstrate a markedly low FR (0.01), indicating minimal danger. The proximity to watercourses significantly influences flooding risk, with a frequency ratio (FR) of 5.33 for places within 100 meters, signifying a high likelihood of flooding, whilst distances exceeding 500 meters yield a FR of 0, indicating negligible danger. Both variables are extensively established in literature as contributors to flood risk; flat locations are more sensitive to water accumulation due to diminished water velocity [36], while regions adjacent to watercourses are vulnerable to overflow occurrences after heavy rains [37].
Low altitudes (922-1500 m) exhibit a FR of 12.93, signifying considerable susceptibility, whereas high altitudes (>3000 m), with a FR of 0, are not impacted. The danger is further influenced by geology, specifically Triassic basalt with a FR of 12.55. A TWI ranging from 3.9 to 5.6 has a remarkably high FR of 95.56, underscoring the significance of water buildup in these areas. The results demonstrate that flat, low-lying regions adjacent to watercourses, with a geology favorable to water accumulation, are the most susceptible to flooding and should be prioritized for risk management interventions.

Model validation and performance evaluation
The examination of the ROC curves for both training and validation datasets underscores the superior efficacy of the models employed to forecast flood susceptibility (Fig. 5). The FR-SVM model demonstrates a remarkable AUC of 92.76% for training data, signifying a strong capability to distinguish between flood-risk locations and those unaffected by flooding. Conversely, the FR-RF model exhibits a marginally lower AUC of 90.59%, whereas the FR-DT model demonstrates the least efficacy with an AUC of 87.81%.
The FR-SVM model demonstrated its robustness on the validation data, with an AUC of 93.32%, so affirming its trustworthiness in predicting sensitive locations. The FR-RF model exhibited an AUC of 91.64%, demonstrating commendable performance, though marginally less effective than the FR-SVM model. The FR-DT model attains the lowest AUC of 89.41%, rendering it the least effective of the three models evaluated. The results demonstrate the superiority of the FR-SVM in both training and validation phases for forecasting flood susceptibility.

FR-SVM model scored the maximum sensitivity (95.88%), signifying an enhanced capacity to identify regions susceptible to flooding. Boasting a specificity of 97.64%, it surpasses other models in minimizing false alarms. The model’s accuracy (96.74%) and precision (97.69%) establish it as the optimal performer for accurately detecting susceptible areas while reducing classification errors (Fig. 6).

Flood susceptibility map evaluation
A hybridization technique was employed to achieve precise flood susceptibility mapping by integrating the outcomes of the FR model with three machine learning algorithms: RF, DT, and SVM. This novel methodology employs the outcomes of the FR model as input for the RF, DT, and SVM algorithms, facilitating the creation of customized and precise zoning maps for flood susceptibility. The collection of triggers was employed to train and assess the predicted efficacy of flood occurrence models in the area. The hybridization of models improves the precision of the generated maps, facilitating superior detection of at-risk regions.
Upon visual examination, the maps generated by the FR-DT, FR-RF, and FR-SVM models exhibit a comparable spatial distribution of flood susceptibility levels, with significant discrepancies in the categorization of very high-risk zones. The FR-RF model (Fig. 7 A) demonstrates broader coverage of extremely high-risk areas compared to the other models, especially in the northern and center regions of the catchment. This may indicate a heightened sensitivity of the Random Forest algorithm to flood triggers, facilitating improved identification of crucial regions. The map generated using the FR-DT model (Fig. 7 B) illustrates a more concentrated distribution of extremely high-risk zones, predominantly in river valleys. Conversely, the FR-SVM model (Fig. 7 C) exhibits a more equitable tendency in classifying risk categories, with a significant portion of the region encompassing moderate and high-risk zones. While all maps exhibit a basic consistency in the spatial distribution of susceptibility levels, the FR-RF model tends to overstate extremely high-risk areas, whereas the FR-DT and FR-SVM models emphasize specific zones more effectively. Moreover, FR-SVM model provides a more measured evaluation, presenting a more equitable depiction of the various susceptibility classes. The disparities might be ascribed to the distinct properties of each machine learning algorithm, each exhibiting varying sensitivities to the utilized variables.

The statistically derived maps reveal substantial disparities among the three susceptibility models (FR-RF, FR-DT, and FR-SVM) in the categorization of risk zones. The FR-DT model exhibits the highest proportions for the “very low” (29.52%) and “low” (48.23%) categories, suggesting a propensity to understate at-risk areas, with approximately 77.75% of the region designated as having low flood susceptibility. Conversely, the FR-RF model designates a larger percentage of the area as “high” (16.97%) and “very high” (6.88%), rendering it the most responsive model for identifying at-risk regions. The FR-SVM model exhibits a more equitable distribution, situated between the other two models, with proportions of 19.15% and 41.54% for the “very low” and “low” classes, respectively, and intermediate values for the high-risk categories (Fig. 7 D). In summary, the FR-DT model is more conservative, the FR-RF is more aggressive in identifying high-risk areas, and the FR-SVM offers a balanced approach.
Numerous statistical techniques and machine learning algorithms have been utilized in flood risk assessment [15][19-24]. The exceptional precision of machine learning models in flood risk assessment is highly advantageous for decision-making in flood management within susceptible regions. Hybridization in machine learning models is an excellent technique for enhancing these algorithms to yield more robust predictions, which has been utilized in environmental management [38]. Previously, RF algorithm has demonstrated superior accuracy relative to other machine learning models, including SVM [39]. Conversely, the present study demonstrated that the hybridized FR-SVM model exhibited greater accuracy than FR-RF, underscoring the significance of frequency ratio hybridization in enhancing the predictive accuracy of SVM. Consequently, this methodology may be advised for implementation under similar settings.
Conclusion
This research integrated a statistical frequency ratio model with three machine learning algorithms: Support Vector Machine, Random Forest, and Decision Tree, to assess flood susceptibility in the Oued Lakhdar watershed. The hybridization of the FR statistical model with machine learning models allowed to leverage the advantages of both methodologies. The FR model offers a lucid and interpretable comprehension of the correlations among flood-inducing elements, whereas the machine learning models leverage these correlations to enhance predictive precision. This hybrid methodology enhances mapping efficacy by integrating statistical analysis with the sophisticated predictive powers of machine learning, which is crucial for addressing the intricate issue of forecasting flood susceptibility.
The results indicate superior performance from all three hybrid models, with AUC values of 92.76% for the FR-SVM model in the training dataset and 93.32% in the validation dataset. These results demonstrate a superior capacity to differentiate between flood-prone locations and those that are not. Furthermore, this model attained a sensitivity of 95.88% and a specificity of 97.64%, demonstrating its capacity to reduce false positives while ensuring dependable identification of at-risk locations.
The susceptibility maps produced demonstrate an accurate delineation of zones at elevated risk of flooding, especially in downstream areas and regions adjacent to rivers with gentle slopes. These maps, produced by hybrid models, exhibit a more distinct demarcation of risk zones compared to non-hybrid or solely statistical models. The FR-SVM model has effectively identified regions most susceptible to floods, rendering it a valuable asset for risk management. This methodology may be used to other catchment areas in the future, integrating supplementary data regarding climate change effects and land use alterations. The implementation of sophisticated approaches, such as neural networks or optimization methods utilizing genetic algorithms, could enhance model performance. Incorporating recent extreme occurrences alongside this hybrid strategy would yield more reliable information for proactive flood risk management.
References
- Shafizadeh-Moghadam H, Valavi R, Shahabi H, Chapi K, Shirzadi A. Novel forecasting approaches using combination of machine learning and statistical models for flood susceptibility mapping. J. Environ. Manag. 2018;217. DOI
- Gharakhanlou NM, Perez L. Flood susceptible prediction through the use of geospatial variables and machine learning methods. J. Hydrol. 2023; 617:129121. DOI
- Ghosh A, Kar SK. Application of analytical hierarchy process (AHP) for flood risk assessment: a case study in Malda district of West Bengal, India. Nat. Hazards. 2018; 94(1):349–68. DOI
- Saidi MEM, Saouabe T, El Alaoui El Fels A, El Khalki EM, Hadri A. Hydro-meteorological characteristics and occurrence probability of extreme flood events in Moroccan High Atlas. J. Water Clim. Change. 2020;11(S1):310–21. DOI
- Elghouat A, Algouti A, Algouti A, Baid S, Ezzahzi S, Kabili S, Agli S. Integrated approaches for flash flood susceptibility mapping: spatial modeling and comparative analysis of statistical and machine learning models. A case study of the Rheraya watershed, Morocco. J. Water Clim. Change. 2024;15(8):3624-46. DOI
- Karmaoui A, Balica SF, Messouli M. Analysis of applicability of flood vulnerability index in Pre-Saharan region, a pilot study to assess flood in Southern Morocco. Nat. Hazards Earth Syst. Sci. Discuss. 2016. DOI
- Morocco natural hazards Probabilistic Risk Analysis. World Bank. Building Morocco’s Resilience: Inputs for an Integrated Risk Management Strategy. Washington, DC. 2013
- Loudyi D, Hasnaoui MD, Fekri A. Flood Risk Management Practices in Morocco: Facts and Challenges. Wadi Flash Floods. 2021;35–94. DOI
- Zhao G, Pang B, Xu Z, Yue J, Tu T. Mapping flood susceptibility in mountainous areas on a national scale in China. Sci. Total Environ. 2018;615:1133–42. DOI
- Aichi A, Ikirri M, Haddou MA, Quesada-Román A, Sahoo S, Singha C, Abioui M. Integrated GIS and analytic hierarchy process for flood risk assessment in the Dades Wadi watershed (Central High Atlas, Morocco). Results Earth Sci. 2024;2,100019. DOI
- Bhandari BP, Dhakal S, Tsou CY. Assessing the Prediction Accuracy of Frequency Ratio, Weight of Evidence, Shannon Entropy, and Information Value Methods for Landslide Susceptibility in the Siwalik Hills of Nepal. Sustainability. 2024;16(5): 2092. DOI
- Nkonge LK, Gathenya JM, Kiptala JK, Cheruiyot CK, Petroselli A. An ensemble of weight of evidence and logistic regression for gully erosion susceptibility mapping in the Kakia-Esamburmbur Catchment, Kenya. Water. 2023;15(7),1292. DOI
- Addis A. GIS – based flood susceptibility mapping using frequency ratio and information value models in upper Abay river basin, Ethiopia. Nat. Hazards Res. 2023;3(2):247-56. DOI
- Elsadek WM, Wahba M, Al-Arifi N, Kanae S, El-Rawy M. Scrutinizing the performance of GIS-based analytical Hierarchical process approach and frequency ratio model in flood prediction–Case study of Kakegawa, Japan. Ain Shams Eng. J. 2024;15(2):102453. DOI
- Ait naceur H, Igmoulan B, Namous, Amrhar M, Bourouay O, Ouayah M. A comparative study of different statistical methods for Flood susceptibility assessment: A case study of N’fis basin, Marrakesh High Atlas (Morocco). Disaster Adv. 2021;14(10). DOI
- El-Rawy M, Elsadek WM, De Smedt F. Flash Flood Susceptibility Mapping in Sinai, Egypt Using Hydromorphic Data, Principal Component Analysis and Logistic Regression. Water. 2022;14(15):2434. DOI
- Özay B, Orhan O. Flood susceptibility mapping by best–worst and logistic regression methods in Mersin, Turkey. Environ. Sci. Pollut. Res. 2023; 30(15):45151-70. DOI
- Seydi ST, Kanani-Sadat Y, Hasanlou M, Sahraei R, Chanussot J, Amani M. Comparison of Machine Learning Algorithms for Flood Susceptibility Mapping. Remote Sens. 2022;15(1):192. DOI
- Costache R, Arabameri A, Costache I, Crăciun A, Islam AR, Abba SI, Sahana M, Pandey M, Tin TT, Pham BT. Flood hazard potential evaluation using decision tree state‐of‐the‐art models. Risk Anal. 2024;44(2):439-58. DOI
- Habibi A, Delavar MR, Sadeghian MS, Nazari B. Flood susceptibility mapping and assessment using regularized random forest and naïve bayes algorithms. ISPRS Ann. Photogramm. Remote Sens. Spatial Inf. Sci. 2023 13;X-4/W1-2022:241–8. DOI
- Ganjirad M, Delavar MR. Flood risk mapping using random forest and support vector machine. ISPRS Ann. Photogramm. Remote Sens. Spatial Inf. Sci. 2023;X-4/W1-2022:201–8. DOI
- Rudra RR, Sarkar SK. Artificial neural network for flood susceptibility mapping in Bangladesh. Heliyon. 2023;9(6):e16459. DOI
- Liu J, Wang J, Xiong J, Cheng W, Li Y, Cao Y, He Y, Duan Y, He W, Yang G. Assessment of flood susceptibility mapping using support vector machine, logistic regression and their ensemble techniques in the Belt and Road region. Geocarto Int. 2022;37(25):9817-46. DOI
- Salvati A, Nia AM, Salajegheh A, Ghaderi K, Asl DT, Al‐Ansari N, Solaimani F, Clague JJ. Flood susceptibility mapping using support vector regression and hyper‐parameter optimization. J. Flood Risk Manag. 2023;16(4):e12920. DOI
- Youssef AM, Pourghasemi HR. Landslide susceptibility mapping using machine learning algorithms and comparison of their performance at Abha Basin, Asir Region, Saudi Arabia. Geosci. Front. 2021;12(2):639–55. DOI
- Tehrany MS, Pradhan B, Jebur MN. Flood susceptibility mapping using a novel ensemble weights-of-evidence and support vector machine models in GIS. J. Hydrol. 2014;512:332–43. DOI
- Ait Naceur H, Igmoullan B, Namous M, El Badaoui K, Bammou Y. Landslide susceptibility mapping by remote sensing and GIS using frequency ratio, value of information and logistic regression methods in the N’fis watershed, High Atlas of Marrakech (Morocco). Disaster Adv. 2024;17(10):31–47. DOI
- Wang Y, Fang Z, Hong H, Costache R, Tang X. Flood susceptibility mapping by integrating frequency ratio and index of entropy with multilayer perceptron and classification and regression tree. J. Environ. Manag. 2021;289:112449. DOI
- Rawal B, Agarwal R. Improving accuracy of classification based on C4. 5 decision tree algorithm using big data analytics. In Computational Intelligence in Data Mining: Proceedings of the International Conference on CIDM 2017. Springer, Singapore. 2019:203-11. DOI
- Tsangaratos P, Ilia I. Landslide susceptibility mapping using a modified decision tree classifier in the Xanthi Perfection, Greece. Landslides. 2015;13(2):305–20. DOI
- Yang C, Liu LL, Huang F, Huang L, Wang XM. Machine learning-based landslide susceptibility assessment with optimized ratio of landslide to non-landslide samples. Gondwana Res. 2023;123:198–216. DOI
- Huang Y, Zhao L. Review on landslide susceptibility mapping using support vector machines. CATENA. 2018;165:520–9. DOI
- Thai Pham B, Shirzadi A, Shahabi H, Omidvar E, Singh SK, Sahana M, Talebpour Asl D, Bin Ahmad B, Kim Quoc N, Lee S. Landslide susceptibility assessment by novel hybrid machine learning algorithms. Sustainability. 2019;11(16):4386. DOI
- Chen X, Chen W. GIS-based landslide susceptibility assessment using optimized hybrid machine learning methods. CATENA. 2021;196:104833. DOI
- O’brien RM. A caution regarding rules of thumb for variance inflation factors. Qual. Quant. 2007;41:673-90. DOI
- Alarifi SS, Abdelkareem M, Abdalla F, Alotaibi M. Flash flood hazard mapping using remote sensing and GIS techniques in southwestern Saudi Arabia. Sustainability. 2022;14(21):14145. DOI
- Kumar N, Jha R. GIS-based flood risk mapping: The case study of Kosi River Basin, Bihar, India. Eng. Technol. Appl. Sci. Res. 2023;13(1):9830-6. DOI
- Alsaeed R, Alaji B, Ebrahim M. Predicting turbidity and Aluminum in drinking water treatment plants using Hybrid Network (GA-ANN) and GEP. Drinking Water Eng. Sci. Discuss. 2021. DOI
- Ren H, Pang B, Bai P, Zhao G, Liu S, Liu Y, Li M. Flood Susceptibility Assessment with Random Sampling Strategy in Ensemble Learning (RF and XGBoost). Remote Sens. 2024;16(2):320. DOI
Cite this article:
Ait Naceur, H., Igmoullan, B., Namous, M. Machine learning-based optimization of flood susceptibility mapping in semi-arid zone. DYSONA – Applied Science, 2025;6(1): 145-159. doi: 10.30493/das.2024.483211
